Machine Learning Interviews: The 5 Hardest Topics & How to Ace Them
💡 Struggling with ML interviews? You’re not alone! Many candidates face roadblocks in certain key areas, preventing them from landing their dream AI roles. In this blog, we break down the five toughest topics in machine learning interviews—from mathematical foundations to model deployment—and provide real-world interview questions with expert answers.
🔍 What makes this guide unique? These questions are curated from the real experiences of candidates who successfully cracked top ML and AI interviews. Learn what hiring managers actually ask, how to approach tricky concepts, and avoid common mistakes that cost candidates their offers.
🚀 What you’ll learn:
✅ The 5 hardest ML topics that trip up most candidates
✅ 20+ real interview questions with expert answers
✅ Strategies to avoid overfitting, handle model drift, and optimize ML pipelines
✅ How to explain complex ML concepts in simple, impactful ways
If you’re preparing for a Data Scientist, ML Engineer, or AI Researcher role, this guide will give you the confidence and knowledge to ace your next interview. Let’s get started! 🔥
1️⃣ Mathematical Foundations (Linear Algebra, Probability, and Statistics)
Q1: Explain the difference between covariance and correlation. When would you use one over the other?
📌 Answer:
- Covariance measures the direction of the relationship between two variables. If positive, the variables increase together; if negative, one increases while the other decreases.
- Correlation standardizes covariance between -1 and 1, making it easier to interpret.
- Use case: Covariance is useful for raw relationships, while correlation is preferred when comparing different datasets with varying scales.
Q2: What is the significance of eigenvectors and eigenvalues in machine learning?
📌 Answer:
- Eigenvectors represent the principal directions of data variance.
- Eigenvalues indicate the magnitude of variance along those eigenvectors.
- Example: In PCA (Principal Component Analysis), eigenvectors define new feature axes, and eigenvalues determine their importance.
Q3: Derive Bayes’ Theorem and explain its use in Naïve Bayes classification.
📌 Answer:
Bayes’ theorem:
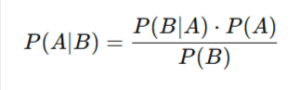
- Used in Naïve Bayes Classifier for spam filtering, sentiment analysis, etc.
- Assumes independence between features to simplify computation.
Q4: How do bias and variance impact the performance of a machine learning model?
📌 Answer:
- High bias → Underfitting (oversimplified model, poor training performance).
- High variance → Overfitting (model memorizes training data, poor generalization).
- Solution: Regularization, feature selection, and cross-validation help balance bias-variance tradeoff.
2️⃣ Gradient Descent & Optimization Techniques
Q5: What is gradient descent? Why do we use learning rate decay?
📌 Answer:
- Gradient Descent minimizes the cost function by iteratively updating weights.
- Learning rate decay reduces step size over time, preventing overshooting and ensuring convergence.
Q6: Explain the vanishing gradient problem. How does ReLU activation help?
📌 Answer:
- Vanishing gradient occurs when gradients become too small, stopping learning (common in deep networks with sigmoid/tanh activations).
- ReLU (Rectified Linear Unit) helps by keeping gradients large for positive values (avoiding saturation).
Q7: Difference between SGD, Momentum, and Adam optimizer?
📌 Answer:

Q8: How does backpropagation work in a neural network?
📌 Answer:
- Forward pass: Compute output from input using weights.
- Compute loss: Compare predicted vs actual values.
- Backward pass: Compute gradients using chain rule.
- Update weights using gradient descent.
3️⃣ Feature Engineering & Data Preprocessing
Q9: Why is feature scaling important? Compare MinMaxScaler vs StandardScaler.
📌 Answer:
- Feature scaling ensures uniform impact across features.
- MinMaxScaler: Scales values between 0 and 1 → Works well for deep learning.
- StandardScaler: Standardizes data to mean 0 and variance 1 → Used in regression & SVM.
Q10: How would you handle missing values in a dataset?
📌 Answer:
- Drop rows (if minimal missing data).
- Mean/median imputation (for numerical features).
- Mode imputation (for categorical data).
- Advanced methods: KNN imputation, MICE (Multiple Imputation).
Q11: What is PCA, and how does it reduce dimensionality?
📌 Answer:
- Principal Component Analysis (PCA) transforms data into new uncorrelated features (principal components).
- Reduces dimensionality while preserving variance, improving model performance.
Q12: How do you identify and remove multicollinearity?
📌 Answer:
- Use Variance Inflation Factor (VIF) → VIF > 10 indicates high multicollinearity.
- Remove correlated features or use PCA.
4️⃣ Overfitting, Regularization & Model Evaluation
Q13: Difference between L1 and L2 regularization?
📌 Answer:
- L1 (Lasso): Shrinks some weights to zero, performing feature selection.
- L2 (Ridge): Shrinks weights towards zero but never eliminates them.
Q14: Difference between precision, recall, and F1-score?
📌 Answer:
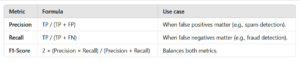
Q15: Why is k-fold cross-validation better than train-test split?
📌 Answer:
- Reduces bias & variance.
- Uses different training/test splits multiple times, ensuring better generalization.
Q16: Your model performs well on training data but poorly on test data. How do you fix it?
📌 Answer:
✅ Reduce overfitting: Use regularization (L1/L2), dropout, or data augmentation.
✅ Increase training data.
✅ Try simpler models or ensemble methods.
5️⃣ ML Model Deployment & Scalability
Q17: What are different ways to deploy an ML model?
📌 Answer:
- Flask/FastAPI API.
- Docker container.
- Cloud (AWS Sagemaker, GCP AI Platform).
Q18: What is model drift? How do you handle it?
📌 Answer:
- Model drift occurs when input data distribution changes over time, reducing model accuracy.
- Solutions: Periodic retraining, monitoring data drift (e.g., Kolmogorov-Smirnov test).
Q19: How would you expose a trained model as an API?
📌 Answer:
- Train & save the model (
jobliborpickle). - Use Flask or FastAPI to create an API.
- Deploy on AWS/GCP/Docker.
Q20: Challenges in scaling an ML model for real-time inference?
📌 Answer:
- Latency issues → Use model quantization.
- Load balancing → Deploy in a distributed system (Kubernetes).
- Monitoring → Set up logging & alerting.